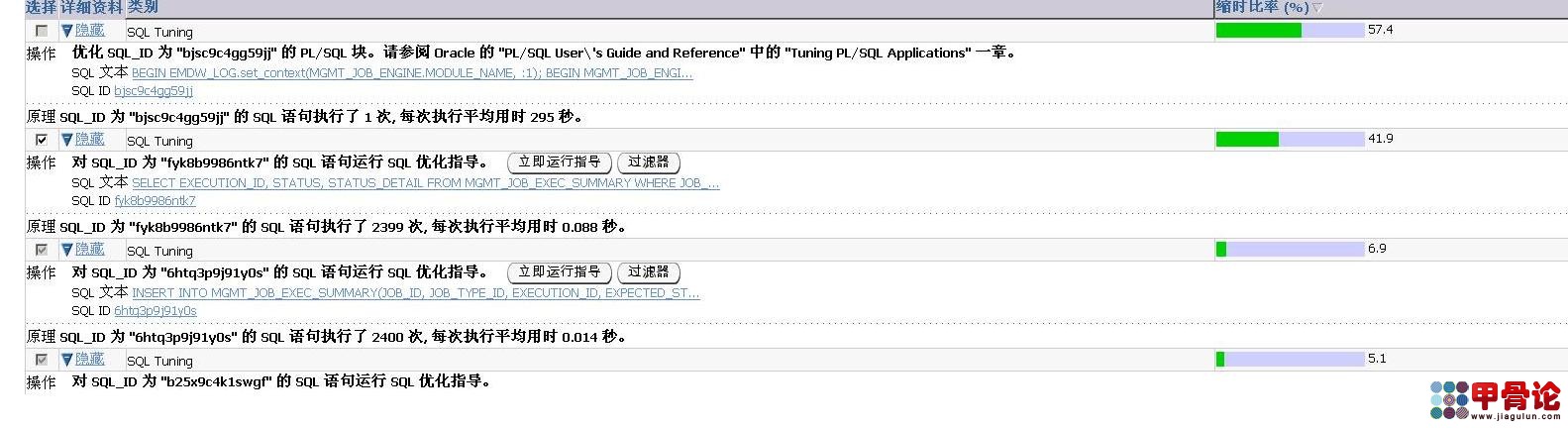
| 我的数据库是11.1.0.6.0。我建的其它库 没有这个问题。但是这个库就出问题。 |
| 你的数据库什么版本,因为oracle 10.2.0.1 for linux的oem就存在问题,我们给质检总局就出现过,oem进程起了很多。是由于oraclebug 引起的。你看看你数据库什么版本,然后去metalink查询一下,应该打上补丁就可以了 |
再补充一点,这个数据库一直没有其他的程序连接,只有developer,sqlplus或企业管理器连接它。所以可以排除是别的程序对表的增删改查出的问题。一定是企业管理器里出了问题。可真是看不出来问题在哪 。请各位老师指教! 。请各位老师指教! |
© 2020 iiDBA Powered by Discuz! X3.4 Comsenz Inc.
iiDBA /
![]() 京ICP备12024223-8号
京ICP备12024223-8号
![]() 不良信息举报电话:13718043309
不良信息举报电话:13718043309